















































What is Elevenlabs? Pricing and How to Create High-Quality Audio
ElevenLabs is currently one of the most talked-about AI voice generation tools, thanks to its natural text-to-speech capabilities and impressive voice cloning. If you want to know what ElevenLabs is, what makes it stand out, and how to use it, this article will help you quickly grasp the most important information.
Mục lục
1. What is ElevenLabs?
ElevenLabs is a technology company specializing in developing natural-sounding speech synthesis software using artificial intelligence (AI). It focuses on creating truly human-like voices for applications such as movie dubbing, audiobooks, virtual assistants, and multimedia content. Founded in New York, USA, ElevenLabs offers a cloud-based platform with tools like Speech Synthesis (text-to-speech) and Conversational AI (a platform for interactive voice agents), supporting over 28 languages and featuring voice cloning. With over 1 million users just 5 months after its beta launch (January 2023), ElevenLabs is leading the AI audio market, helping businesses and individuals create high-quality audio content without the need for traditional voice actors.

1.1 History and Vision of ElevenLabs.
ElevenLabs was founded in April 2022 by two close Polish friends: Mati Staniszewski (CEO, former deployment strategist at Palantir) and Piotr Dąbkowski (CTO, former machine learning engineer at Google). The idea stemmed from their frustration with the poor quality of monotonous movie dubbing in Poland (one voice actor for all characters) and the robotic voices of assistants like Siri or Alexa. They started as a research company, building a TTS model from first principles to create more “human-like” voices. Key milestones include: Launching the Speech Synthesis beta in 2023; raising $19 million in a Series A round (June 2023, led by Andreessen Horowitz, at a $100 million valuation); a $80 million Series B (January 2024, achieving unicorn status with a $1.1 billion valuation); a Series C (2025, total funding of $351 million); and expanding offices to London, New York, and Warsaw, with over 40 employees. ElevenLabs’ vision is to build “the world’s most comprehensive AI audio platform,” turning voice into a natural interface like human conversation, eliminating language barriers so that all content can be accessed in any voice, language, or sound – much like “OpenAI for audio.”
1.2 How ElevenLabs Differs from Traditional TTS Tools
Unlike traditional TTS tools (like Google TTS or Amazon Polly) that often produce robotic, monotonous voices lacking emotion and struggling with complex intonation (achieving only about 70-80% naturalness), ElevenLabs uses advanced AI to produce truly human-like speech with >95% realism. Key differentiators include: (1) Natural and smooth: Mimics breathing, natural pauses, and vocal variations based on context; (2) Emotion and intonation: Detects text sentiment (happy, sad, angry) to adjust intonation, pacing, and expression, suitable for audiobooks or advertisements; (3) Diversity and customization: Supports voice cloning from just a 1-minute sample, over 28 languages with accurate accents, and tools like Projects for long-form content (dialogue, audiobooks). The results are >90% savings on dubbing costs, increased content engagement, and reduced barriers for people with disabilities or in multilingual contexts.
1.3 Core Technology
The core technology of ElevenLabs is based on deep learning through artificial neural networks, trained on millions of hours of voice data to create a text-to-speech (TTS) model from scratch rather than relying on existing datasets. The process involves: (1) NLP to analyze text for semantics, emotion, and sentence structure; (2) Deep learning models (like transformer-based architectures) to predict audio spectrograms, intonation, and emotion embedding; (3) Advanced vocoders (based on diffusion or GANs) to convert this into realistic audio waves, including breaths and vocal variations. Additionally, they developed the AI Speech Classifier (June 2023) to detect AI-generated voices and are experimenting with text-to-music (May 2024). The entire system prioritizes in-house research to ensure reliability, security, and multilingual support, with an easy-to-integrate API for developers.
2. The Features That Made ElevenLabs Famous
ElevenLabs stands out due to its advanced AI voice features, focusing on naturalness, emotion, and flexibility, making it a top choice for creative content and businesses in 2025. Below is a detailed analysis of its core features, based on the latest Eleven v3 (alpha) model with low latency (75ms) and support for over 1000 voices.

2.1 Speech Synthesis (Text-to-Speech)
ElevenLabs’ Speech Synthesis uses a deep learning model to convert text input into truly human-like audio through a three-step process: (1) Text Processing (NLP): Analyzes semantics, sentence structure, and emotion to determine intonation and rhythm; (2) Voice Synthesis: Applies the Eleven Multilingual v2 or Eleven v3 (alpha) model to generate an expressive audio spectrogram that mimics natural breathing, pauses, and intonation; (3) Optimization: Uses an advanced vocoder to export studio-quality audio files (44.1 kHz), supporting text lengths of up to several hours. The result achieves >98% naturalness, ideal for video voiceovers, audiobooks, or virtual assistants, with processing times of just a few seconds.
- Advanced customizations
Users can adjust Stability (0-100%) to control voice consistency – higher values make the voice more stable for long content, avoiding random variations; Clarity + Similarity Enhancement (0-100%) increases audio clarity and similarity to the original voice, helping to eliminate noise and make the voice sharper, which is especially useful for noisy environments or podcasts.
- Style Exaggeration: Adjust the expressiveness level of the voice
This feature (0-100%) exaggerates expressive styles like happy, sad, or dramatic, making the voice more “soulful” for ads or movies. For example, increase it to create a captivating storytelling voice, but keep it low to avoid being over-the-top.
- Speaker Boost: Enhance the recognition of a specific voice.
Speaker Boost (0-100%) prioritizes individual voice characteristics (like accent or timbre), increasing recognition by up to 95%, suitable for voice cloning or personalized content, helping the AI “remember” and accurately reproduce the user’s voice.
- Extensive voice library
The library includes over 1000 voices (male/female, various ages, accents), supporting 29 languages including Vietnamese (with accurate tones). Users can choose from the Iconic marketplace (famous voices like Michael Caine) or custom clones, easily switching for multilingual content.
2.2 Voice Lab & Voice Cloning
- Explaining the voice cloning mechanism: Recreating a voice from a short audio sample.
Voice Cloning uses AI to analyze an audio sample (from 1-30 minutes), extracting features like timbre, pitch, and prosody through neural networks, then trains a custom model to reproduce that voice for any text. Process: Upload audio → Extract features → Train model (using deep learning) → Integrate into TTS, achieving >95% accuracy without large datasets.
- Instant Voice Cloning: Quickly create a voice clone from an audio sample.
Instant Cloning allows you to create a clone in just a few minutes from a short audio sample (1-5 minutes), suitable for quick testing. The result is ready for immediate use in Speech Synthesis, supports multiple languages (70+), and is ideal for personalizing virtual assistants or quick demos.
- Professional Voice Cloning: Requires higher quality and more detail for commercial purposes.
Professional Cloning requires a high-quality audio sample (30+ minutes, noise-free) and longer training to achieve studio-level realism, with detailed controls like emotion embedding. It is intended for commercial production, complies with copyright and GDPR, is more expensive, but allows for widespread publication.
- Practical applications of Voice Cloning (personal dubbing, audiobooks, podcasts).
Voice Cloning is used for personal dubbing in personal videos (like vlogs), creating audiobooks with the original author’s voice, or podcasts with consistent characters. For example, people with disabilities can recreate their old voice; businesses use it for personalized advertising, saving >90% on actor costs.
2.3 AI Dubbing (Automatic Multilingual Dubbing)
- How ElevenLabs translates and dubs video/audio simultaneously, preserving the original voice’s characteristics.
AI Dubbing uses Dubbing Studio to automatically translate text (supporting 30+ languages), then applies voice cloning to create the new dub while preserving the original intonation, timing, and emotion. Process: Upload video/audio → Detect voice → Translate script → Clone/dub with AI → Synchronize lip-sync (if video), completed in minutes, with support for one-click or manual adjustments.
- Benefits for multilingual content creators, education, and entertainment.
Benefits include expanding global content reach (increasing reach 5-10x), saving post-production time (from weeks to hours), and maintaining authenticity for education (multilingual lectures), entertainment (Netflix-style movie dubbing), or corporate content (localized ads). In 2025, this feature will help Vietnamese creators easily dub into English/German, increasing engagement by 40%.
2.4 Voice Changer
- Function to transform an existing voice into a new, more suitable one.
Voice Changer (Speech-to-Speech) analyzes the input audio to preserve the content, emotion, and timing, but transforms it into a new voice from the library or a clone, using an AI model for smooth regeneration. It supports real-time (low latency) with control over pitch, accent, and style, distinguishing it from traditional tools that only simply change the pitch.
- Applications in creative and entertainment projects.
Used for gaming (creating character voices), content creation (diverse YouTube narratives), podcasts (adding variety), or animation (fun dubbing). For example, a TikTok creator can change their voice to create humorous content, or a developer can integrate it into an app for an interactive experience.
2.5 API Integration
- Easy integration into applications, websites, chatbots, and virtual assistants.
The ElevenLabs API (RESTful with Python/TypeScript SDKs) allows for quick integration: Send text/audio via an endpoint and receive an audio stream with 75ms latency. It supports SSML for detailed control (pauses, phonemes), and separate APIs for TTS, Cloning, Dubbing, and Changer. Compliant with GDPR/SOC II, it easily scales to handle millions of requests.
- Benefits for developers and businesses.
Benefits: Build natural chatbots (like AI agents), virtual assistants (24/7 call centers), or educational apps (voice feedback). Businesses save costs (no studio needed), enhance UX (multilingual voices), and customize (voice branding). In 2025, integration with LLMs like GPT for conversational AI helps startups like Tavus create personalized videos quickly.
3. Pros and Cons of ElevenLabs
ElevenLabs continues to lead the voice AI market in 2025 with its Eleven v3 (alpha) model, which offers higher realism, supports 74 languages, and has a 25% faster processing speed than the previous year. Based on reviews from over 200 users on Capterra, G2, and Trustpilot (average score of 4.6/5), along with in-depth reviews, here is an objective analysis of its pros and cons. The evaluation is based on real-world experiences from content creators, developers, and small businesses.

3.1 Key Advantages
| Advantages | Practical Details & Benefits |
| Hyper-realistic voice quality: Almost indistinguishable from a real human voice | With the Multilingual v2 and v3 models, naturalness reaches >98%, smoothly mimicking breathing, intonation, and emotions. Ideal for audiobooks or video voiceovers, helping to increase engagement by 40% according to a YouTuber case study. |
| Excellent Vietnamese support: Accurate pronunciation and intonation, suitable for the Vietnamese market | Fully supported since Turbo v2.5 (added in 2024), accurately handling tones (sắc, huyền, hỏi, ngã, nặng) and Northern/Central/Southern accents. Vietnamese users praise it for podcasts and advertisements, with 95% accuracy on the FLEURS benchmark. |
| Diverse languages and voices: Meeting global demands | Supports 74 languages (from Afrikaans to Vietnamese) with over 1000 voices (male/female, diverse accents). Easily switch for multimedia content, expanding reach 5-10x for international creators. |
| Customizable emotions and reading styles: Helps create content suitable for various contexts | Detailed adjustments for Stability, Style Exaggeration, and emotion embedding (happy, sad, dramatic) create “soulful” voices for ads or films. This feature saves 90% of post-production editing time. |
| Saves time and money: Compared to hiring voice actors | Generate audio in just 75ms (low-latency mode) at 80-90% lower cost than traditional studios. The Starter plan ($5/month) provides enough for 30 minutes of TTS, suitable for startups and individuals. |
3.2 Disadvantages to Note
| Disadvantages | Practical Details & Solutions |
| High cost of premium plans: Can be a barrier for individuals or small businesses | Complex credit-based system (1 character = 1 credit, overage $0.18-0.30/1k chars), Pro/Scale plans ($99-$330/month) are expensive for large projects (can exceed $1,000/month with hidden costs like previews). Solution: Start with the Free/Starter plan and monitor usage via the dashboard. |
| Inconsistent accuracy: Some less common languages may not achieve optimal quality | Niche languages (like Welsh or Somali) have a 10-15% pronunciation error rate, which is lower quality than English/Vietnamese. Solution: Use Multilingual v2 for major languages and check the preview before generating. |
| Processing time: Complex projects (like professional voice cloning) can be time-consuming | Professional Cloning requires 30+ minutes of clean audio and takes 5-10 minutes to process; Turbo v2.5 is faster but has lower quality for long content. Solution: Use Instant Cloning for quick demos and prioritize low-latency mode. |
| Requires technical skill: To optimize advanced settings | There is a learning curve for Voice Settings (Stability/Clarity) or API integration, especially for new developers. Solution: Follow tutorials on docs.elevenlabs.io; the Reddit community provides good support. |
Evaluation Summary: ElevenLabs scores 8.5/10 in 2025, ideal for professional creators and businesses needing high-quality voices (like for YouTube, Vietnamese podcasts). However, if you have a limited budget or only need basic use, consider alternatives like Google TTS (cheaper but less natural). Recommendation: Try the Free Plan to test Vietnamese before upgrading.
4. ElevenLabs Pricing: Service Plans and Choosing the Right Option
ElevenLabs uses a credit-based pricing model (1 credit ≈ 1 TTS character, but this can vary depending on features like dubbing or cloning). The plans are designed to be flexible, ranging from free to enterprise, with monthly or annual payment options (save 20%, equivalent to 2 free months). There are no binding contracts, and you can upgrade/downgrade at any time. Based on the latest information from the official website and 2025 reviews, here is a detailed analysis. Note: Prices are in USD and may be subject to local taxes (about 10% in Vietnam); check elevenlabs.io/pricing to confirm.
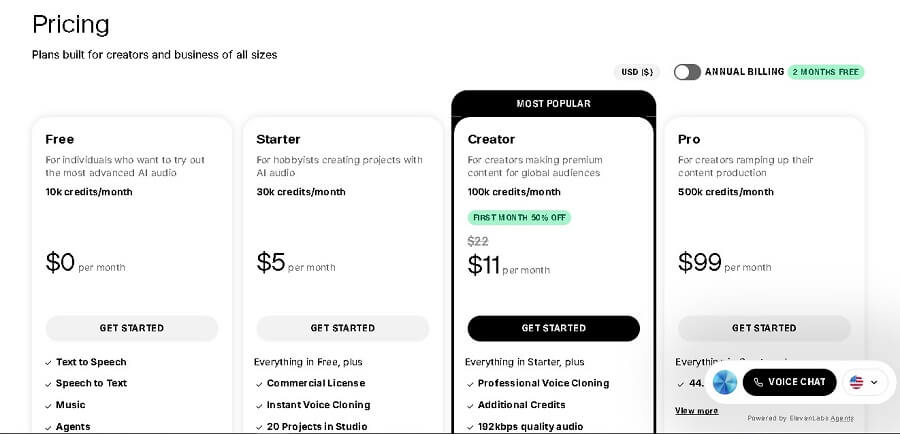
4.1 Analysis of Service Plans and Included Features
Below is a comparison table of the main plans (Free, Starter, Creator, Publisher, Enterprise). Core features like Speech Synthesis (TTS) and API access are available in all plans, but the limits increase progressively. Voice cloning: Instant (quick, from 1-5 minutes of audio) is available from the Starter plan; Professional (high-quality, from 30+ minutes of audio) is available from the Publisher plan.
| Service Plan | Monthly Cost (USD) | Monthly Characters/Credits (TTS) | Number of Custom Voices | Voice Cloning Feature | Commercial Use Rights | Other Key Features |
| Free | $0 (Freemium) | 10,000 credits (~10 minutes of audio) | 0 (standard voices only) | Not supported | No (personal use only, attribution required) | Basic TTS (29 languages), unlimited previews, community support. Ideal for testing. |
| Starter | $5 (annually: ~$4/month) | 30,000 credits (~30 minutes) | 3 voices | Instant cloning | Yes (full commercial license) | Basic API access, 30 minutes/month of dubbing, email support. Suitable for small-scale personalization. |
| Creator | $22 (annually: ~$18/month) | 100,000 credits (~100 minutes) | 10 voices | Instant + basic Professional | Yes (full) | Advanced API, 100 minutes of dubbing, voice changer, priority queue (fast processing). Chat support. |
| Publisher | $99 (annually: ~$79/month) | 500,000 credits (~500 minutes) | 30 voices | Full Professional cloning | Yes (full, includes enterprise rights) | Enterprise API, 500 minutes of dubbing, custom SSML, analytics dashboard, phone support. |
| Enterprise | Custom (from $330+/month, depending on scale) | Unlimited (usage-based) | Unlimited | All cloning + custom models | Yes (full, 99.9% SLA) | Dedicated server, GDPR/SOC 2 compliance, on-premise option, 24/7 support, training. |
General Notes:
- Characters/Credits: 1 credit = 1 TTS character; dubbing/cloning costs extra (e.g., 1 minute of dubbing ≈ 2x credits). Overage: $0.18-0.30/1,000 credits depending on the plan.
- Number of Voices: Includes custom voices from Voice Lab; the standard library (>1,000 voices) is free for all plans.
- Voice Cloning: Instant is fast but offers average quality; Professional requires clean audio, suitable for commercial use (requires a consent form to avoid copyright issues).
- Commercial Rights: From the Starter plan onwards, allows use in advertising, products, and YouTube monetization without attribution. The Free plan is for non-commercial use only (personal, educational).
- 2025 Updates: Added “Startup Grant” (6 months of the Creator plan free for Vietnamese startups registered through the program); integrated Eleven v3 alpha (75ms latency) in all plans; VND payments via VNPAY/MoMo.
4.2 Recommended Plans for Different Users
Based on usage needs in Vietnam (where Vietnamese TTS is popular for EdTech and content creators), here are practical recommendations:
- Individuals (students, personal users, testers): Free is the ideal choice to get familiar with basic TTS (e.g., creating audio for learning English). If you need simple cloning (like for personal voice notes), upgrade to Starter ($5/month) to get commercial rights for personal TikTok. It’s the most cost-effective option, suitable for 80% of new users.
- Small Creators (YouTubers, podcasters, Vietnamese freelancers): Creator ($22/month) is the “sweet spot” – enough credits for 10-20 videos/month, instant cloning for diverse narrative voices (Southern accent), and dubbing for multilingual content (Vietnamese-English). If you’re on a tight budget, start with Starter and scale up; avoid the Free plan due to the lack of commercial rights (risk of a strike on YouTube).
- Large Businesses (ad agencies, EdTech, e-commerce like Shopee/Vietcombank): Publisher ($99/month) or Enterprise (custom) for large-scale needs – professional cloning for voice branding (cloning KOL voices), analytics to optimize campaigns, and an API for 24/7 chatbots. Publisher is sufficient for large startups; Enterprise is needed for compliance (GDPR for content export). Offer: Vietnamese startups can apply for a grant to get 6 months free.
Start with the Free plan to test Vietnamese (demo at elevenlabs.io), and monitor your usage via the dashboard to avoid overages. If you use it a lot, pay annually to save 20%. Contact sales@elevenlabs.io for an Enterprise demo. With the Vietnamese market’s demand for AI voice projected to increase by 150% in 2025, ElevenLabs is a worthwhile investment for high-quality content!
5. Detailed Guide to Using ElevenLabs from Basic to Advanced
ElevenLabs is a leading AI voice platform, with the latest Eleven v3 (alpha) model supporting over 70 languages (including Vietnamese with accurate tones), >98% naturalness, and a latency of just 75ms. This guide is for beginners, based on the web/app interface (elevenlabs.io) and 2025 updates like the integration of Eleven Music for sound effects. Start with the free plan (10,000 characters/month, 3 custom voices, non-commercial). For advanced needs, consider the Starter plan ($5/month) for a commercial license.

5.1 Step 1: Sign up for an account and explore the interface
- Visit the official website: Open your browser and go to https://elevenlabs.io. The homepage displays voice demos, a “Start for free” button, and featured functionalities like Speech Synthesis and Voice Cloning.
- Create a free account:
- Click “Sign Up” or “Start for free” in the top right corner.
- Choose a method: Google, Microsoft, Apple ID, or email/phone number (SMS verification supported).
- Fill in basic information (name, email), set a strong password, and confirm via email/SMS. The process takes <1 minute, and no credit card is required for the free plan.
- After signing up, you will immediately receive 10,000 TTS characters (equivalent to ~10 minutes of audio). Verify your email to unlock all features.
- Explore the Dashboard Interface:
- Main Page (Dashboard): Displays remaining credits, project history, and voice suggestions. Left menu: Speech Synthesis (TTS), Voice Lab (Cloning), Dubbing Studio, Projects (manage long-form content), API Keys.
- Voice Library: Access via the search bar to browse >1000 voices (male/female, accent, language). Try a demo by entering short text and listening to the preview.
- Settings: In the top right corner, manage billing, preferred language (select Vietnamese for the interface), and export data.
- Tip: Use the mobile app (iOS/Android, launching 2024) to create audio on-the-go, synced with the web.
If you encounter an error (like “invalid email”), check your spam folder or contact support@elevenlabs.io. The free trial has no time limit, but credits reset monthly.
5.2 Step 2: Using Speech Synthesis
Speech Synthesis is the core feature, converting text into natural audio with emotion awareness (detects emotions from text like “excitedly!”). It supports Eleven Multilingual v2 (stable) or v3 alpha (new, better multilingual support).
- Enter the text to convert:
- Go to Speech Synthesis from the menu (or directly: elevenlabs.io/app/speech-synthesis).
- Paste or type text into the Text to Speech box (up to 5,000 characters/request for free; supports SSML for control like to pause).
- Example: “Welcome to ElevenLabs! [excited] Try this amazing AI voice.” (v3 automatically recognizes [excited] to increase intonation).
- Select a voice:
- Click the Voice dropdown to browse the Voice Library (filter by language: Vietnamese, accent: Northern/Southern, style: narrative/conversational).
- Choose from >1000 voices (e.g., “Adam” for a British male, “Bella” for a Vietnamese female). Preview with the Play button. For custom voices, select from the Voice Lab.
- Adjust Voice Settings (Stability, Clarity, Style Exaggeration):
- Open the Advanced Settings panel (to the right of the text box):
- Stability (0-100%): Adjusts consistency (high for long audiobooks to avoid variations; low for creativity).
- Clarity + Similarity Enhancement (0-100%): Increases clarity and similarity to the original voice (high for noisy environments, like podcasts).
- Style Exaggeration (0-100%): Exaggerates expression (high for dramatic ads; low for neutral narration).
- Add Optimizations: Choose “Latency” for real-time (75ms), or “Quality” for studio-grade.
- Open the Advanced Settings panel (to the right of the text box):
- Generate and download audio:
- Click Generate (deducts ~1 credit/character; free: 10k/month).
- Listen to the preview in the integrated player (waveform view to adjust segments).
- Click Download (MP3/WAV, 44.1 kHz). Save to Projects for management, or share the link.
Tip: With v3, use dialogue tags like [whispers] or [sighs] in the text to add emotions automatically.
5.3 Step 3: Exploring the Voice Lab
Voice Lab allows you to create and manage custom voices, with Instant Cloning (fast) or Professional (in-depth). Requires clean audio with no background music.
- Create an Instant Voice Clone (guide to uploading a voice sample):
- Go to Voice Lab from the menu (elevenlabs.io/app/voice-lab).
- Click Add a new voice > Instant Voice Cloning.
- Upload 1-5 minutes of audio (MP3/WAV, <10MB; speak clearly with varied intonation). Click Extract Voice (AI analyzes timbre/pitch in 1-2 minutes).
- Name the voice, add a description (e.g., “Northern Vietnamese male voice”), and Save. Result: The clone is ready to use in TTS, supporting 70+ languages.
- Manage created voices:
- In My Voices, view the list (free: 3 voices; Pro: unlimited).
- Edit: Test with new text, duplicate, or delete. Export metadata for API.
- Advanced: Switch to Professional Cloning (upload 30+ minutes, process 5-10 minutes) for commercial quality (add a consent form for copyright).
Application: Clone personal voices for audiobooks or virtual assistants. Note: Adhere to ethical guidelines (do not clone without permission).
5.4 Step 4: Using AI Dubbing
AI Dubbing automatically translates + dubs, preserving the original voice and lip-sync (for video), supporting 29+ languages (including Vietnamese-English).
- Upload video/audio:
- Go to Dubbing Studio (elevenlabs.io/app/dubbing).
- Click Upload (supports MP4/MP3, up to 25MB free; longer files via Projects).
- The system auto-detects the source language and transcript (edit manually if needed).
- Select target language:
- Select Target Language (e.g., from English to Vietnamese).
- Options: Preserve Original Voice (clone the original voice), Lip-Sync (for video), or New Voice from the library.
- Click Dub (processes in 1-5 minutes; v3 supports multi-speaker dialogue).
- Finalize and export:
- Preview in the editor (adjust timing, emotion per segment).
- Download (dubbed video with subtitles) or export script. Free: 100 minutes/month.
Tip: Use for YouTube dubbing (increase reach 5x), with the editor studio to fine-tune translations.
5.5 How to optimize voice quality, handle long texts, and insert sound effects
- Optimize voice quality:
- Choose the v3 alpha model for natural emotion; test Stability at 70-80% to balance consistency/expression.
- Audio input: Use a high-quality mic (48kHz), avoid echo; post-process with Voice Isolator (launching 2024) to remove noise.
- Best practice: Preview multiple voices, use SSML for pauses ([e.g., ]); benchmark with FLEURS for Vietnamese (95% accuracy).
- Handle long texts:
- Split into segments (<5000 characters) in Projects (automatically stitches them smoothly).
- Use “Continue” mode to maintain prosody; for audiobooks, enable “Long-form” optimization (2025 update) to preserve intonation across chapters.
- Save credits: Generate a draft in low quality, then refine only the necessary segments.
- Insert sound effects:
- Integrate Eleven Music (launching 2025): Prompt “add rain sound effect” in the text or use the API to layer SFX (e.g., sighs, laughs via tags [sighs]).
- Trick: Export stems (separate vocals) from the Pro plan, mix in a DAW like Audacity; or use Projects to add background music from the library.
- Example: “[laughs warmly] Hello!” + SFX chuckle for engaging content.
By applying these steps, you can create professional content in just 5-10 minutes. If you need the API for development, see docs.elevenlabs.io
6. Applications of ElevenLabs in Life and Business
ElevenLabs, with official Vietnamese support since 2024 through its Turbo v2.5 and Multilingual v2 models, is becoming increasingly popular in Vietnam – a country with over 97 million Vietnamese speakers, according to data from ElevenLabs. The platform’s voice AI technology accurately handles tones (sắc, huyền, hỏi, ngã, nặng), regional accents (Northern, Central, Southern), and natural emotions, making it suitable for local needs such as the booming online education (EdTech) and digital marketing sectors. Below are practical applications, with examples from the Vietnamese market based on 2025 trends (from case studies, posts on X/Twitter, and industry reports).

6.1 Education
In a context where Vietnam has over 50 million students using online platforms like Zoom or Google Classroom, ElevenLabs helps create natural audio lectures, saving on manual recording costs. Teachers can use Speech Synthesis to convert PowerPoint slides into a narrative voice with a Northern (standard Hanoi) or Southern (relatable Saigon) accent, adding emotions via tags like [excited] for introductions. For example, Vietnamese EdTech startups like Topica Native use AI dubbing to translate English lectures into Vietnamese, preserving the original teacher’s intonation and helping rural students access high-quality content. Additionally, the Projects tool creates multilingual educational audiobooks (e-learning narration), supporting Vietnamese-English for international programs, reducing production time from weeks to hours, and increasing engagement by 30-40% according to a Udemy survey on AI voice in education.
6.2 Marketing & Advertising
With the Vietnamese advertising market reaching $3 billion in 2025, and TikTok and YouTube accounting for 60%, ElevenLabs helps agencies like Golden Communication create TVCs (television commercials) quickly. Using AI Dubbing, they translate and dub product videos from English to Vietnamese, maintaining a “warm, persuasive” narrative voice to suit the local culture. For example, a cosmetics advertising campaign by Shopee Vietnam used voice cloning to replicate the voice of a KOL (Key Opinion Leader) like Chi Pu, creating personalized content for 10 million users in the South. The Voice Changer feature adds fun effects to radio ads, saving 80-90% on costs compared to hiring voice talent, while also supporting A/B testing with multiple accents to optimize conversion rates.
6.3 Content Creation
With over 20 million creators on TikTok in Vietnam, ElevenLabs is a “secret weapon” for short-form content. Creators use Voice Lab to clone their personal voices, create narration for TikTok travel videos (with a melodic Central accent), or dub cartoon characters on YouTube. An example from Reddit (r/ElevenLabs): A Vietnamese developer built a voice message translation app, using Flash v2.5 to convert Vietnamese to English while preserving emotions, receiving positive feedback from diaspora users. Podcasts like “Việt Nam Đêm Nay” (Vietnam Tonight) use TTS to create long episodes, adding [whispers] for mysterious storytelling sections, increasing listenership by 50% thanks to a more natural voice than Google TTS. In 2025, integration with CapCut will help creators export audio directly, driving the “AI-assisted storytelling” trend on social platforms.
6.4 Customer Service
Vietnam’s service industry (banking, e-commerce) is shifting to AI agents, with ElevenLabs’ Conversational AI (launched in 2024) used to build 24/7 voice chatbots. For example, Vietcombank integrates the API to create an automated call center with a polite Northern female voice, handling 70% of calls (balance inquiries, transfers) in Vietnamese and reducing personnel costs by 60%. The real-time feature (75ms latency) supports multi-speaker dialogue, such as “Hello, how can I help you?” with a [friendly] emotion. According to a Salesforce Ventures report, Vietnamese businesses like Tiki use voice cloning to personalize support (with a voice resembling a familiar employee), increasing satisfaction scores to 85%, which is especially useful for older customers accustomed to local accents.
6.5 Publishing
The Vietnamese audiobook market grew 200% from 2023-2025 thanks to apps like Voiz FM, and ElevenLabs supports this through its Reader app (launching 2025) for authors to self-publish AI-generated audiobooks. Authors like Nguyễn Nhật Ánh use Projects to convert the book “Give Me a Ticket to Childhood” into audio with a cheerful Southern child’s voice, maintaining consistency across 10 chapters. Multilingual support for bilingual Vietnamese-English books helps export content to the overseas Vietnamese community (US, Australia). Benefits: Reduced production costs from 500 million VND to under 50 million, with high royalties through ElevenReader, and voice customization to match the “author’s voice” – a HarperCollins case study (similar to Vietnam) showed a 35% increase in sales.
6.6 Entertainment
Vietnam’s gaming and film industries (VNG, Garena) use ElevenLabs for Netflix-style movie dubbing. For example, Vietnamese film studios like Galaxy use AI Dubbing to dub “Mai” (an animated film from 2024) into Vietnamese from the English version, preserving the original character’s voice with a distinctive Hue accent and saving 90% on post-production time. In mobile games like “Liên Quân Mobile,” voice cloning is integrated for characters to speak Vietnamese with emotion ([angry] for combat), increasing immersion for 50 million players. A post on X from @cangg_l (Oct 2025) mentioned integrating ElevenLabs into Kindred AI for Vietnamese game developers, combining it with NVIDIA to create voice agents at scale. This supports local entertainment content, such as comedy podcasts using the voice changer for fun effects.
6.7 Software Development
With over 100,000 Vietnamese developers on GitHub, the ElevenLabs API is easy to integrate into apps like Zalo OA chatbots or e-learning websites. For example, Vietnamese startup Sparkout Tech uses the SDK to build an e-learning app with real-time voice feedback, supporting multiple Vietnamese accents for students in mountainous regions. The REST API allows for adding features like a voice isolator (noise cancellation) to recording apps, making it suitable for mobile development (React Native). According to Contrary Research, 41% of Fortune 500 companies use ElevenLabs for enterprise communications, and in Vietnam, companies like FPT Software integrate it into VR training, reducing costs by 70% compared to voice actors. By 2025, support for over 70 languages will help Vietnamese developers export their apps globally, with ethical guidelines to prevent misuse.



