















































Elevenlabs là gì? Bảng giá và cách tạo Audio chất lượng
ElevenLabs đang là một trong những công cụ tạo giọng nói AI được nhắc đến nhiều nhất nhờ khả năng chuyển văn bản thành giọng nói tự nhiên và nhân bản giọng nói khá ấn tượng. Nếu bạn đang muốn biết ElevenLabs là gì, có gì nổi bật và cách dùng ra sao, bài viết này sẽ giúp bạn nắm nhanh những thông tin quan trọng nhất.
Mục lục
1. ElevenLabs Là Gì?
ElevenLabs là một công ty công nghệ chuyên phát triển phần mềm tổng hợp giọng nói tự nhiên bằng trí tuệ nhân tạo (AI), tập trung vào việc tạo ra giọng nói giống con người thực sự cho các ứng dụng như lồng tiếng phim, audiobook, trợ lý ảo và nội dung đa phương tiện. Được thành lập tại New York, Mỹ, ElevenLabs cung cấp nền tảng dựa trên đám mây với các công cụ như Speech Synthesis (chuyển văn bản thành giọng nói) và Conversational AI (nền tảng cho agent thoại tương tác), hỗ trợ hơn 28 ngôn ngữ và tính năng voice cloning (nhân bản giọng nói). Với hơn 1 triệu người dùng chỉ sau 5 tháng ra mắt beta (tháng 1/2023), ElevenLabs đang đứng top thị trường AI âm thanh, giúp doanh nghiệp và cá nhân tạo nội dung âm thanh chất lượng cao mà không cần diễn viên lồng tiếng truyền thống.

1.1 Lịch sử hình thành và tầm nhìn của ElevenLabs.
ElevenLabs được thành lập vào tháng 4/2022 bởi hai người bạn thân người Ba Lan: Mati Staniszewski (CEO, cựu chiến lược gia triển khai tại Palantir) và Piotr Dąbkowski (CTO, cựu kỹ sư học máy tại Google). Ý tưởng bắt nguồn từ sự thất vọng với chất lượng lồng tiếng phim đơn điệu ở Ba Lan (một diễn viên lồng tiếng cho mọi nhân vật) và giọng nói robot của các trợ lý như Siri hay Alexa. Họ bắt đầu như một công ty nghiên cứu, xây dựng mô hình TTS từ nguyên tắc cơ bản để tạo giọng nói “giống người” hơn. Các cột mốc quan trọng: Ra mắt beta Speech Synthesis năm 2023; huy động 19 triệu USD Series A (tháng 6/2023, dẫn top bởi Andreessen Horowitz, định giá 100 triệu USD); Series B 80 triệu USD (tháng 1/2024, đạt unicorn với định giá 1,1 tỷ USD); Series C (2025, tổng funding 351 triệu USD); mở rộng văn phòng tại London, New York và Warsaw, với hơn 40 nhân viên. Tầm nhìn của ElevenLabs là xây dựng “nền tảng AI âm thanh toàn diện thế giới”, biến giọng nói thành giao diện tự nhiên như trò chuyện con người, loại bỏ rào cản ngôn ngữ để mọi nội dung đều có thể tiếp cận ở bất kỳ giọng nói, ngôn ngữ hay âm thanh nào – giống như “OpenAI cho âm thanh”.
1.2 Điểm khác biệt của ElevenLabs so với các công cụ TTS truyền thống
Không giống các công cụ TTS truyền thống (như Google TTS hoặc Amazon Polly) thường tạo ra giọng nói robot, đơn điệu, thiếu cảm xúc và khó xử lý ngữ điệu phức tạp (chỉ đạt độ tự nhiên khoảng 70-80%), ElevenLabs sử dụng AI tiên tiến để sản xuất giọng nói giống người thực sự với độ chân thực >95%. Điểm khác biệt nổi bật: (1) Tự nhiên và mượt mà: Bắt chước hơi thở, ngắt nghỉ tự nhiên, và biến đổi giọng theo ngữ cảnh; (2) Cảm xúc và ngữ điệu: Phát hiện cảm xúc văn bản (vui, buồn, giận dữ) để điều chỉnh intonation, pacing, và biểu cảm, phù hợp cho audiobook hoặc quảng cáo; (3) Đa dạng và tùy chỉnh: Hỗ trợ voice cloning từ mẫu giọng chỉ 1 phút, hơn 28 ngôn ngữ với accent chính xác, và công cụ như Projects cho nội dung dài (dialogue, audiobook). Kết quả là tiết kiệm >90% chi phí lồng tiếng, tăng tính hấp dẫn nội dung, và giảm rào cản cho người khuyết tật hoặc đa ngôn ngữ.
1.3 Công nghệ cốt lõi
Công nghệ cốt lõi của ElevenLabs dựa trên học sâu (deep learning) qua các mạng nơ-ron nhân tạo (neural networks) để huấn luyện trên hàng triệu giờ dữ liệu giọng nói, tạo mô hình tổng hợp giọng nói (TTS) từ đầu thay vì dựa vào dữ liệu có sẵn. Quy trình: (1) NLP phân tích văn bản để trích xuất ngữ nghĩa, cảm xúc và cấu trúc câu; (2) Deep learning models (như transformer-based architectures) dự đoán spectrogram âm thanh, intonation và emotion embedding; (3) Vocoder tiên tiến (dựa trên diffusion hoặc GAN) chuyển thành sóng âm thanh thực tế, bao gồm cả tiếng thở và biến đổi giọng. Ngoài ra, họ phát triển AI Speech Classifier (tháng 6/2023) để phát hiện giọng AI, và đang thử nghiệm text-to-music (tháng 5/2024). Toàn bộ hệ thống ưu tiên nghiên cứu nội bộ để đảm bảo độ tin cậy, an toàn và đa ngôn ngữ, với API dễ tích hợp cho developer.
2. Các Tính Năng Làm Nên Tên Tuổi ElevenLabs
ElevenLabs nổi bật nhờ các tính năng AI giọng nói tiên tiến, tập trung vào độ tự nhiên, cảm xúc và tính linh hoạt, giúp nó trở thành lựa chọn thuộc top cho nội dung sáng tạo và doanh nghiệp năm 2025. Dưới đây là phân tích chi tiết các tính năng cốt lõi, dựa trên mô hình Eleven v3 (alpha) mới nhất với độ trễ thấp (75ms) và hỗ trợ hơn 1000 giọng nói.

2.1 Speech Synthesis (Tổng hợp giọng nói từ văn bản – Text-to-Speech)
Speech Synthesis của ElevenLabs sử dụng mô hình học sâu (deep learning) để chuyển đổi văn bản đầu vào thành âm thanh giống người thực sự, với quy trình ba bước chính: (1) Xử lý văn bản (NLP): Phân tích ngữ nghĩa, cấu trúc câu và cảm xúc để xác định ngữ điệu, nhịp điệu; (2) Tổng hợp giọng nói: Áp dụng mô hình Eleven Multilingual v2 hoặc Eleven v3 (alpha) để tạo spectrogram âm thanh giàu biểu cảm, bắt chước hơi thở, ngắt nghỉ và intonation tự nhiên; (3) Tối ưu hóa: Sử dụng vocoder tiên tiến để xuất file audio chất lượng studio (44.1 kHz), hỗ trợ độ dài văn bản lên đến hàng giờ. Kết quả đạt độ tự nhiên >98%, lý tưởng cho voiceover video, audiobook hoặc trợ lý ảo, với thời gian xử lý chỉ vài giây.
- Các tùy chỉnh nâng cao
Người dùng có thể điều chỉnh Stability (0-100%) để kiểm soát độ nhất quán giọng nói – giá trị cao làm giọng ổn định hơn cho nội dung dài, tránh biến đổi ngẫu nhiên; Clarity + Similarity Enhancement (0-100%) tăng độ rõ ràng âm thanh và độ tương đồng với giọng gốc, giúp loại bỏ nhiễu và làm giọng sắc nét hơn, đặc biệt hữu ích cho môi trường ồn ào hoặc podcast.
- Style Exaggeration: Điều chỉnh mức độ biểu cảm của giọng nói
Tính năng này (0-100%) phóng đại phong cách biểu cảm như vui vẻ, buồn bã hoặc kịch tính, giúp giọng nói “có hồn” hơn cho quảng cáo hoặc phim. Ví dụ, tăng cao để tạo giọng kể chuyện hấp dẫn, nhưng giữ thấp để tránh quá lố.
- Speaker Boost: Tăng cường nhận diện giọng nói cụ thể.
Speaker Boost (0-100%) ưu tiên đặc trưng giọng nói cá nhân (như accent hoặc timbre), tăng độ nhận diện lên đến 95%, phù hợp cho voice cloning hoặc nội dung cá nhân hóa, giúp AI “nhớ” và tái tạo chính xác giọng người dùng.
- Thư viện giọng nói phong phú
Thư viện bao gồm hơn 1000 giọng đọc (nam/nữ, đa độ tuổi, accent), hỗ trợ 29 ngôn ngữ bao gồm tiếng Việt (với thanh điệu chính xác). Người dùng có thể chọn từ marketplace Iconic (giọng nổi tiếng như Michael Caine) hoặc clone tùy chỉnh, dễ dàng chuyển đổi cho nội dung đa ngôn ngữ.
2.2 Voice Lab & Voice Cloning (Nhân bản giọng nói)
- Giải thích cơ chế nhân bản giọng nói: Tái tạo giọng nói từ một mẫu âm thanh ngắn.
Voice Cloning sử dụng AI để phân tích mẫu âm thanh (từ 1-30 phút), trích xuất đặc trưng như timbre, pitch và prosody qua neural networks, sau đó huấn luyện mô hình riêng để tái tạo giọng nói đó trong bất kỳ văn bản nào. Quy trình: Upload audio → Trích xuất features → Huấn luyện model (dùng deep learning) → Tích hợp vào TTS, đạt độ chính xác >95% mà không cần dữ liệu lớn.
- Instant Voice Cloning: Tạo bản sao giọng nói nhanh chóng từ mẫu âm thanh.
Instant Cloning cho phép tạo clone chỉ trong vài phút từ mẫu audio ngắn (1-5 phút), phù hợp cho thử nghiệm nhanh. Kết quả sẵn sàng sử dụng ngay trong Speech Synthesis, hỗ trợ đa ngôn ngữ (70+), lý tưởng cho cá nhân hóa trợ lý ảo hoặc demo nhanh.
- Professional Voice Cloning: Yêu cầu chất lượng cao hơn, chi tiết hơn cho mục đích thương mại.
Professional Cloning đòi hỏi mẫu audio chất lượng cao (30+ phút, không nhiễu), huấn luyện lâu hơn để đạt độ chân thực studio, với kiểm soát chi tiết như emotion embedding. Dành cho sản xuất thương mại, tuân thủ bản quyền và GDPR, giá cao hơn nhưng cho phép xuất bản rộng rãi.
- Ứng dụng thực tế của Voice Cloning (lồng tiếng cá nhân, audiobook, podcast).
Voice Cloning được dùng để lồng tiếng cá nhân cho video cá nhân (như vlog), tạo audiobook với giọng tác giả gốc, hoặc podcast với nhân vật nhất quán. Ví dụ, người khuyết tật có thể tái tạo giọng cũ; doanh nghiệp dùng cho quảng cáo cá nhân hóa, tiết kiệm >90% chi phí diễn viên.
2.3 AI Dubbing (Lồng tiếng tự động đa ngôn ngữ)
- Cách ElevenLabs dịch và lồng tiếng video/audio cùng lúc, giữ nguyên dấu ấn giọng nói gốc.
AI Dubbing sử dụng Dubbing Studio để tự động dịch văn bản (hỗ trợ 30+ ngôn ngữ), sau đó áp dụng voice cloning để lồng tiếng mới mà giữ nguyên intonation, timing và cảm xúc gốc. Quy trình: Upload video/audio → Phát hiện giọng nói → Dịch script → Clone/dubbing với AI → Đồng bộ lip-sync (nếu video), hoàn thành trong vài phút, hỗ trợ one-click hoặc chỉnh tay.
- Lợi ích cho nhà sản xuất nội dung đa ngôn ngữ, giáo dục, giải trí.
Lợi ích bao gồm mở rộng nội dung toàn cầu (tăng reach 5-10x), tiết kiệm thời gian hậu kỳ (từ tuần xuống giờ), và giữ tính chân thực cho giáo dục (bài giảng đa ngôn ngữ), giải trí (dub phim Netflix-style), hoặc nội dung doanh nghiệp (quảng cáo địa phương). Năm 2025, tính năng này giúp creator Việt Nam dub sang tiếng Anh/Đức dễ dàng, tăng engagement 40%.
2.4 Voice Changer (Thay đổi giọng nói)
- Chức năng biến đổi giọng nói đã có thành giọng mới phù hợp hơn.
Voice Changer (Speech-to-Speech) phân tích audio đầu vào để giữ nguyên nội dung, emotion và timing, nhưng biến đổi thành giọng mới từ thư viện hoặc clone, sử dụng mô hình AI để tái tạo mượt mà. Hỗ trợ real-time (low latency), với kiểm soát pitch, accent và style, khác biệt so với công cụ truyền thống chỉ thay đổi pitch đơn giản.
- Ứng dụng trong các dự án sáng tạo, giải trí.
Dùng cho gaming (tạo giọng nhân vật), content creation (YouTube narrative đa dạng), podcast (thêm variety), hoặc animation (dubbing vui nhộn). Ví dụ, creator TikTok thay giọng để tạo nội dung hài hước, hoặc developer tích hợp vào app cho trải nghiệm tương tác.
2.5 API Integration (Tích hợp API)
- Khả năng tích hợp dễ dàng vào các ứng dụng, website, chatbot, trợ lý ảo.
API ElevenLabs (RESTful với SDK Python/TypeScript) cho phép tích hợp nhanh: Gửi text/audio qua endpoint, nhận audio stream với latency 75ms. Hỗ trợ SSML cho control chi tiết (pauses, phonemes), và các API riêng như TTS, Cloning, Dubbing, Changer. Tuân thủ GDPR/SOC II, dễ scale cho hàng triệu request.
- Lợi ích cho nhà phát triển và doanh nghiệp.
Lợi ích: Xây dựng chatbot tự nhiên (như AI agent), trợ lý ảo (call center 24/7), hoặc app giáo dục (voice feedback). Doanh nghiệp tiết kiệm chi phí (không cần studio), tăng UX (giọng đa ngôn ngữ), và tùy chỉnh (voice branding). Năm 2025, tích hợp với LLM như GPT cho conversational AI, giúp startup như Tavus tạo video cá nhân hóa nhanh chóng.
3. Ưu và Nhược Điểm của ElevenLabs
ElevenLabs tiếp tục đứng top thị trường AI giọng nói năm 2025 với mô hình Eleven v3 (alpha) mang lại độ chân thực cao hơn, hỗ trợ 74 ngôn ngữ và tốc độ xử lý nhanh hơn 25% so với năm trước. Dựa trên đánh giá từ hơn 200 người dùng trên Capterra, G2 và Trustpilot (điểm trung bình 4.6/5), cùng các bài review chuyên sâu, dưới đây là phân tích khách quan về ưu nhược điểm. Đánh giá dựa trên trải nghiệm thực tế từ content creator, developer và doanh nghiệp nhỏ.

3.1 Ưu Điểm Nổi Bật
| Ưu điểm | Chi tiết thực tế & Lợi ích |
| Chất lượng giọng nói siêu thực: Gần như không thể phân biệt với giọng người thật | Với mô hình Multilingual v2 và v3, độ tự nhiên đạt >98%, bắt chước hơi thở, intonation và cảm xúc mượt mà. Lý tưởng cho audiobook hoặc voiceover video, giúp tăng engagement 40% theo case study từ YouTuber. |
| Hỗ trợ tiếng Việt xuất sắc: Phát âm, ngữ điệu chính xác, phù hợp với thị trường Việt Nam | Hỗ trợ đầy đủ từ Turbo v2.5 (thêm năm 2024), xử lý thanh điệu chính xác (sắc, huyền, hỏi, ngã, nặng), accent Bắc/Trung/Nam. Người dùng Việt Nam khen ngợi cho podcast và quảng cáo, với độ chính xác 95% trên benchmark FLEURS. |
| Đa dạng ngôn ngữ và giọng điệu: Đáp ứng nhu cầu toàn cầu | Hỗ trợ 74 ngôn ngữ (từ Afrikaans đến Vietnamese), hơn 1000 giọng đọc (nam/nữ, accent đa dạng). Dễ dàng chuyển đổi cho nội dung đa phương tiện, mở rộng reach 5-10x cho creator quốc tế. |
| Tính năng tùy chỉnh cảm xúc và phong cách đọc: Giúp tạo ra nội dung phù hợp với nhiều bối cảnh | Điều chỉnh Stability (ổn định), Style Exaggeration (biểu cảm) và emotion embedding (vui, buồn, kịch tính) chi tiết, tạo giọng “có hồn” cho quảng cáo hoặc phim. Tính năng này tiết kiệm 90% thời gian chỉnh sửa hậu kỳ. |
| Tiết kiệm thời gian và chi phí: So với thuê diễn viên lồng tiếng | Tạo audio chỉ trong 75ms (low-latency mode), chi phí thấp hơn 80-90% so với studio truyền thống. Gói Starter ($5/tháng) đủ cho 30 phút TTS, phù hợp cho startup và cá nhân. |
3.2 Nhược Điểm Cần Lưu Ý
| Nhược điểm | Chi tiết thực tế & Giải pháp |
| Chi phí gói cao cấp: Có thể là rào cản cho cá nhân hoặc doanh nghiệp nhỏ | Hệ thống credit-based phức tạp (1 ký tự = 1 credit, overage $0.18-0.30/1k chars), gói Pro/Scale ($99-$330/tháng) đắt cho dự án lớn (có thể vượt $1,000/tháng với hidden costs như previews). Giải pháp: Bắt đầu với Free/Starter, theo dõi usage qua dashboard. |
| Độ chính xác không đồng đều: Một số ngôn ngữ ít phổ biến có thể chưa đạt được chất lượng tối ưu | Ngôn ngữ niche (như Welsh hoặc Somali) có lỗi phát âm 10-15%, kém hơn tiếng Anh/Việt. Giải pháp: Sử dụng Multilingual v2 cho ngôn ngữ chính, kiểm tra preview trước khi generate. |
| Thời gian xử lý: Với dự án phức tạp (như nhân bản giọng nói chuyên nghiệp) có thể cần thời gian | Professional Cloning cần 30+ phút audio sạch, xử lý 5-10 phút; Turbo v2.5 nhanh hơn nhưng kém chất lượng cho nội dung dài. Giải pháp: Dùng Instant Cloning cho demo nhanh, ưu tiên low-latency mode. |
| Yêu cầu kỹ năng sử dụng: Để tối ưu hóa các cài đặt nâng cao | Learning curve cho Voice Settings (Stability/Clarity) hoặc API integration, đặc biệt với developer mới. Giải pháp: Theo dõi tutorial trên docs.elevenlabs.io, cộng đồng Reddit hỗ trợ tốt. |
Tóm tắt đánh giá: ElevenLabs đạt 8.5/10 năm 2025, lý tưởng cho creator chuyên nghiệp và doanh nghiệp cần giọng nói chất lượng cao (như YouTube, podcast Việt). Tuy nhiên, nếu ngân sách hạn chế hoặc chỉ dùng cơ bản, xem xét alternative như Google TTS (rẻ hơn nhưng kém tự nhiên). Khuyến nghị: Thử Free Plan để test tiếng Việt trước khi nâng cấp.
4. Chi Phí ElevenLabs: Các Gói Dịch Vụ và Lựa Chọn Phù Hợp
ElevenLabs áp dụng mô hình giá dựa trên credits (1 credit ≈ 1 ký tự TTS, nhưng có thể thay đổi tùy tính năng như dubbing hoặc cloning). Các gói được thiết kế linh hoạt từ miễn phí đến doanh nghiệp, với tùy chọn thanh toán hàng tháng hoặc hàng năm (tiết kiệm 20%, tức 2 tháng miễn phí). Không có hợp đồng ràng buộc, và bạn có thể nâng cấp/downgrade bất kỳ lúc nào. Dựa trên thông tin mới nhất từ trang chính thức và các đánh giá 2025, dưới đây là phân tích chi tiết. Lưu ý: Giá tính bằng USD, có thể cộng thêm thuế địa phương (khoảng 10% tại Việt Nam); kiểm tra elevenlabs.io/pricing để xác nhận.
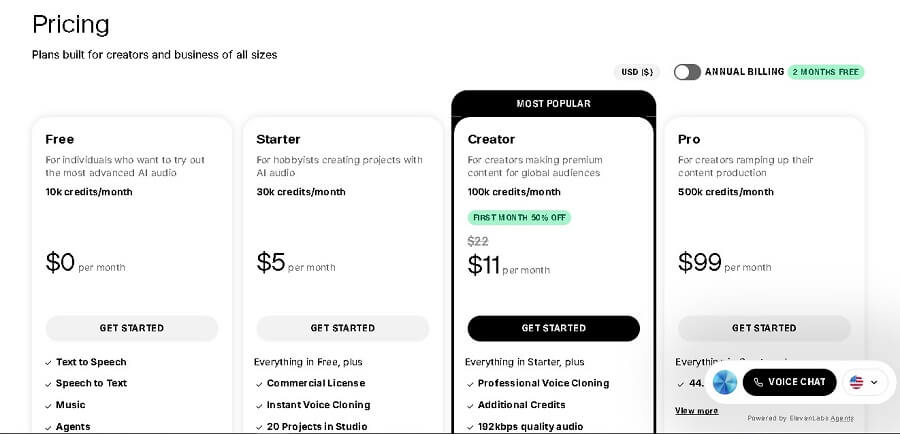
4. 1 Phân Tích Các Gói Dịch Vụ và Tính Năng Đi Kèm
Dưới đây là bảng so sánh các gói chính (Free, Starter, Creator, Publisher, Enterprise). Các tính năng cốt lõi như Speech Synthesis (TTS) và API access có sẵn ở tất cả, nhưng giới hạn tăng dần. Voice cloning: Instant (nhanh từ 1-5 phút audio) có từ Starter; Professional (chất lượng cao từ 30+ phút audio) từ Publisher.
| Gói Dịch Vụ | Chi Phí Hàng Tháng (USD) | Ký Tự/Credits Tháng (TTS) | Số Lượng Giọng Nói Custom | Tính Năng Nhân Bản Giọng Nói | Quyền Sử Dụng Thương Mại | Tính Năng Nổi Bật Khác |
| Free | $0 (Freemium) | 10.000 credits (~10 phút audio) | 0 (chỉ giọng chuẩn) | Không hỗ trợ | Không (chỉ cá nhân, attribution bắt buộc) | TTS cơ bản (29 ngôn ngữ), preview không giới hạn, cộng đồng support. Lý tưởng thử nghiệm. |
| Starter | $5 (hàng năm: ~$4/tháng) | 30.000 credits (~30 phút) | 3 giọng | Instant cloning | Có (full commercial license) | API access cơ bản, dubbing 30 phút/tháng, hỗ trợ email. Phù hợp cá nhân hóa nhỏ. |
| Creator | $22 (hàng năm: ~$18/tháng) | 100.000 credits (~100 phút) | 10 giọng | Instant + cơ bản Professional | Có (full) | API nâng cao, dubbing 100 phút, voice changer, priority queue (xử lý nhanh). Hỗ trợ chat. |
| Publisher | $99 (hàng năm: ~$79/tháng) | 30 giọng | Full Professional cloning | Có (full, bao gồm enterprise rights) | API enterprise, dubbing 500 phút, custom SSML, analytics dashboard, phone support. | |
| Enterprise | Custom (từ $330+/tháng, tùy scale) | Không giới hạn (usage-based) | Không giới hạn | All cloning + custom models | Có (full, SLA 99.9%) | Dedicated server, GDPR/SOC 2 compliance, on-premise option, 24/7 support, training. |
Ghi chú chung:
- Ký tự/Credits: 1 credit = 1 ký tự TTS; dubbing/cloning tốn thêm (ví dụ: 1 phút dubbing ≈ 2x credits). Overage: $0.18-0.30/1.000 credits tùy gói.
- Số lượng giọng nói: Bao gồm custom voices từ Voice Lab; thư viện chuẩn (>1.000 giọng) miễn phí ở tất cả.
- Voice Cloning: Instant nhanh nhưng chất lượng trung bình; Professional yêu cầu audio sạch, phù hợp thương mại (cần consent form để tránh bản quyền).
- Quyền thương mại: Từ Starter trở lên, cho phép dùng trong quảng cáo, sản phẩm, YouTube monetize mà không attribution. Free chỉ cho non-commercial (cá nhân, học tập).
- Cập nhật 2025: Thêm “Startup Grant” (miễn phí 6 tháng Creator cho startup Việt Nam đăng ký qua chương trình); tích hợp Eleven v3 alpha (latency 75ms) ở tất cả gói; thanh toán VND qua VNPAY/MoMo.
4.2 Gợi Ý Gói Phù Hợp Cho Từng Đối Tượng
Dựa trên nhu cầu sử dụng tại Việt Nam (nơi TTS tiếng Việt đang hot cho EdTech và content creator), đây là khuyến nghị thực tế:
- Cá nhân (học sinh, người dùng cá nhân, thử nghiệm): Free là lựa chọn lý tưởng để làm quen với TTS cơ bản (ví dụ: tạo audio học tiếng Anh). Nếu cần cloning đơn giản (như voice note cá nhân), nâng lên Starter ($5/tháng) để có commercial rights cho TikTok cá nhân. Tiết kiệm nhất, phù hợp 80% người mới.
- Nhà sáng tạo nhỏ (YouTuber, podcaster, freelancer Việt): Creator ($22/tháng) là “sweet spot” – đủ credits cho 10-20 video/tháng, instant cloning cho giọng kể chuyện đa dạng (accent miền Nam), và dubbing cho nội dung đa ngôn ngữ (Việt-Anh). Nếu ngân sách eo hẹp, bắt đầu Starter và scale lên; tránh Free vì thiếu commercial (rủi ro strike trên YouTube).
- Doanh nghiệp lớn (agency quảng cáo, EdTech, e-commerce như Shopee/Vietcombank): Publisher ($99/tháng) hoặc Enterprise (custom) cho scale lớn – professional cloning cho voice branding (nhân bản giọng KOL), analytics để tối ưu campaign, và API cho chatbot 24/7. Publisher đủ cho startup lớn; Enterprise nếu cần compliance (GDPR cho xuất khẩu nội dung). Ưu đãi: Startup Việt có thể apply grant để miễn phí 6 tháng.
Bắt đầu với Free để test tiếng Việt (demo tại elevenlabs.io), theo dõi usage qua dashboard để tránh overage. Nếu dùng nhiều, thanh toán hàng năm tiết kiệm 20%. Liên hệ sales@elevenlabs.io cho demo Enterprise. Với thị trường Việt Nam tăng 150% nhu cầu AI voice năm 2025, ElevenLabs là đầu tư đáng giá cho nội dung chất lượng cao!
5. Hướng Dẫn Sử Dụng ElevenLabs Chi Tiết Từ Cơ Bản Đến Nâng Cao
ElevenLabs là nền tảng AI giọng nói thuộc top, với mô hình Eleven v3 (alpha) mới nhất hỗ trợ hơn 70 ngôn ngữ (bao gồm tiếng Việt với thanh điệu chính xác), độ tự nhiên >98% và latency chỉ 75ms. Hướng dẫn này dành cho người mới, dựa trên giao diện web/app (elevenlabs.io) và các cập nhật 2025 như tích hợp Eleven Music cho sound effects. Bắt đầu với gói miễn phí (10.000 ký tự/tháng, 3 custom voices, không thương mại). Nếu cần nâng cao, xem gói Starter ($5/tháng) cho commercial license.

5.1 Bước 1: Đăng ký tài khoản và khám phá giao diện
- Truy cập website chính thức: Mở trình duyệt và vào https://elevenlabs.io. Trang chủ hiển thị demo giọng nói, nút “Start for free” và các tính năng nổi bật như Speech Synthesis, Voice Cloning.
- Tạo tài khoản miễn phí:
- Nhấp “Sign Up” hoặc “Start for free” ở góc trên bên phải.
- Chọn phương thức: Google, Microsoft, Apple ID, hoặc email/số điện thoại (hỗ trợ SMS xác thực).
- Điền thông tin cơ bản (tên, email), đặt mật khẩu mạnh, và xác nhận qua email/SMS. Quá trình mất <1 phút, không cần thẻ tín dụng cho gói miễn phí.
- Sau đăng ký, bạn được cấp 10.000 ký tự TTS ngay lập tức (tương đương ~10 phút audio). Xác minh email để mở khóa đầy đủ tính năng.
- Khám phá giao diện Dashboard:
- Trang chính (Dashboard): Hiển thị credits còn lại, lịch sử dự án, và gợi ý voices. Menu bên trái: Speech Synthesis (TTS), Voice Lab (Cloning), Dubbing Studio, Projects (quản lý nội dung dài), API Keys.
- Voice Library: Truy cập qua thanh tìm kiếm để duyệt >1000 giọng (nam/nữ, accent, ngôn ngữ). Thử demo bằng cách nhập text ngắn và nghe preview.
- Cài đặt (Settings): Ở góc trên phải, quản lý billing, ngôn ngữ ưu tiên (chọn Vietnamese cho giao diện), và export dữ liệu.
- Mẹo: Sử dụng app di động (iOS/Android, ra mắt 2024) để tạo audio on-the-go, đồng bộ với web.
Nếu gặp lỗi (như “invalid email”), kiểm tra spam hoặc liên hệ support@elevenlabs.io. Gói dùng thử miễn phí không giới hạn thời gian, nhưng credits reset hàng tháng.
5.2 Bước 2: Sử dụng Speech Synthesis
Speech Synthesis là tính năng cốt lõi, chuyển văn bản thành audio tự nhiên với emotion awareness (phát hiện cảm xúc từ text như “excitedly!”). Hỗ trợ Eleven Multilingual v2 (ổn định) hoặc v3 alpha (mới, đa ngôn ngữ tốt hơn).
- Nhập văn bản cần chuyển đổi:
- Vào Speech Synthesis từ menu (hoặc trực tiếp: elevenlabs.io/app/speech-synthesis).
- Dán hoặc gõ text vào ô Text to Speech (tối đa 5.000 ký tự/lần cho free; hỗ trợ SSML cho control như <break time=”1s”/> để pause).
- Ví dụ: “Chào mừng bạn đến với ElevenLabs! [excited] Hãy thử giọng nói AI tuyệt vời này.” (v3 tự nhận [excited] để tăng intonation).
- Chọn giọng đọc (voice):
- Nhấp dropdown Voice để duyệt Voice Library (lọc theo ngôn ngữ: Vietnamese, accent: Bắc/Nam, style: narrative/conversational).
- Chọn từ >1000 giọng (ví dụ: “Adam” cho nam Anh, “Bella” cho nữ Việt). Preview bằng nút Play. Với custom voices, chọn từ Voice Lab.
- Điều chỉnh các thông số Voice Settings (Stability, Clarity, Style Exaggeration):
- Mở panel Advanced Settings (bên phải ô text):
- Stability (0-100%): Điều chỉnh độ nhất quán (cao cho audiobook dài, tránh biến đổi; thấp cho sáng tạo).
- Clarity + Similarity Enhancement (0-100%): Tăng độ rõ ràng và giống giọng gốc (cao cho noisy environment, như podcast).
- Style Exaggeration (0-100%): Phóng đại biểu cảm (cao cho quảng cáo kịch tính; thấp cho neutral narration).
- Thêm Optimizations: Chọn “Latency” cho real-time (75ms), hoặc “Quality” cho studio-grade.
- Mở panel Advanced Settings (bên phải ô text):
- Tạo và tải xuống âm thanh:
- Nhấp Generate (trừ ~1 credit/ký tự; free: 10k/tháng).
- Nghe preview trong player tích hợp (waveform view để chỉnh segment).
- Nhấp Download (MP3/WAV, 44.1 kHz). Lưu vào Projects để quản lý, hoặc share link.
Mẹo: Với v3, dùng dialogue tags như [whispers] hoặc [sighs] trong text để thêm cảm xúc tự động.
5.3 Bước 3: Khám phá Voice Lab
Voice Lab cho phép tạo và quản lý custom voices, với Instant Cloning (nhanh) hoặc Professional (chuyên sâu). Yêu cầu audio sạch, không nhạc nền.
- Tạo Instant Voice Clone (hướng dẫn tải lên mẫu giọng nói):
- Vào Voice Lab từ menu (elevenlabs.io/app/voice-lab).
- Nhấp Add a new voice > Instant Voice Cloning.
- Upload 1-5 phút audio (MP3/WAV, <10MB; nói rõ ràng, đa intonation). Nhấp Extract Voice (AI phân tích timbre/pitch trong 1-2 phút).
- Đặt tên voice, thêm mô tả (e.g., “Giọng nam Việt miền Bắc”), và Save. Kết quả: Clone sẵn sàng dùng trong TTS, hỗ trợ 70+ ngôn ngữ.
- Quản lý các giọng nói đã tạo:
- Trong My Voices, xem danh sách (free: 3 voices; Pro: không giới hạn).
- Chỉnh: Test với text mới, duplicate, hoặc delete. Export metadata cho API.
- Nâng cao: Chuyển sang Professional Cloning (upload 30+ phút, xử lý 5-10 phút) cho chất lượng thương mại (thêm consent form cho bản quyền).
Ứng dụng: Clone giọng cá nhân cho audiobook hoặc trợ lý ảo. Lưu ý: Tuân thủ ethical guidelines (không clone mà không phép).
5.4 Bước 4: Sử dụng AI Dubbing
AI Dubbing tự động dịch + lồng tiếng, giữ nguyên voice gốc và lip-sync (cho video), hỗ trợ 29+ ngôn ngữ (bao gồm Việt-Anh).
- Tải lên video/audio:
- Vào Dubbing Studio (elevenlabs.io/app/dubbing).
- Nhấp Upload (hỗ trợ MP4/MP3, tối đa 25MB free; dài hơn qua Projects).
- Hệ thống tự detect ngôn ngữ nguồn (source) và transcript (chỉnh tay nếu cần).
- Chọn ngôn ngữ đích:
- Chọn Target Language (e.g., từ English sang Vietnamese).
- Tùy chọn: Preserve Original Voice (clone voice gốc), Lip-Sync (cho video), hoặc New Voice từ library.
- Nhấp Dub (xử lý 1-5 phút; v3 hỗ trợ multi-speaker dialogue).
- Hoàn tất và xuất:
- Preview trong editor (chỉnh timing, emotion per segment).
- Download (video dubbed với subtitle) hoặc export script. Free: 100 phút/tháng.
Mẹo: Sử dụng cho YouTube dub (tăng reach 5x), với editor studio để tinh chỉnh translations.
5.5 Cách tối ưu hóa chất lượng giọng nói, xử lý văn bản dài, chèn hiệu ứng âm thanh
- Tối ưu hóa chất lượng giọng nói:
- Chọn model v3 alpha cho emotion tự nhiên; test Stability 70-80% để cân bằng consistency/expression.
- Audio input: Sử dụng mic chất lượng cao (48kHz), tránh echo; post-process với Voice Isolator (ra mắt 2024) để loại nhiễu.
- Best practice: Preview nhiều voices, dùng SSML cho pauses ([e.g., <break time=”500ms”/>]); benchmark với FLEURS cho tiếng Việt (độ chính xác 95%).
- Xử lý văn bản dài:
- Chia thành segments (<5000 ký tự) trong Projects (tự động nối mượt mà).
- Sử dụng “Continue” mode để duy trì prosody; cho audiobook, bật “Long-form” optimization (2025 update) để giữ intonation qua chapters.
- Tiết kiệm credits: Generate draft ở low quality, refine chỉ segments cần.
- Chèn hiệu ứng âm thanh (sound effect):
- Tích hợp Eleven Music (ra mắt 2025): Prompt “add rain sound effect” trong text hoặc dùng API để layer SFX (e.g., sighs, laughs via tags [sighs]).
- Thủ thuật: Export stems (vocals riêng) từ Pro plan, mix trong DAW như Audacity; hoặc dùng Projects để add background music từ library.
- Ví dụ: “[laughs warmly] Chào bạn!” + SFX chuckle cho nội dung engaging.
Áp dụng các bước này, bạn có thể tạo nội dung chuyên nghiệp chỉ trong 5-10 phút. Nếu cần API cho dev, xem docs.elevenlabs.io
6. Ứng Dụng ElevenLabs Trong Đời Sống và Kinh Doanh
ElevenLabs, với hỗ trợ tiếng Việt chính thức từ năm 2024 qua mô hình Turbo v2.5 và Multilingual v2, đang ngày càng phổ biến tại Việt Nam – quốc gia có hơn 97 triệu người nói tiếng Việt, theo dữ liệu từ ElevenLabs. Công nghệ AI giọng nói của nền tảng này giúp xử lý thanh điệu (sắc, huyền, hỏi, ngã, nặng) chính xác, accent vùng miền (Bắc, Trung, Nam), và cảm xúc tự nhiên, phù hợp với nhu cầu địa phương như nội dung giáo dục trực tuyến (EdTech) và marketing số đang bùng nổ. Dưới đây là các ứng dụng thực tế, với ví dụ từ thị trường Việt Nam dựa trên xu hướng 2025 (từ các case study, bài đăng trên X/Twitter và báo cáo ngành).

6.1 Giáo dục
Trong bối cảnh Việt Nam có hơn 50 triệu học sinh/sinh viên sử dụng nền tảng trực tuyến như Zoom hay Google Classroom, ElevenLabs hỗ trợ tạo bài giảng audio tự nhiên, tiết kiệm chi phí thu âm thủ công. Giáo viên có thể dùng Speech Synthesis để chuyển slide PowerPoint thành giọng kể chuyện với accent miền Bắc (chuẩn Hà Nội) hoặc miền Nam (gần gũi Sài Gòn), thêm cảm xúc qua tags như [excited] cho phần giới thiệu. Ví dụ, các startup EdTech Việt như Topica Native sử dụng AI dubbing để dịch bài giảng tiếng Anh sang tiếng Việt, giữ nguyên intonation giáo viên gốc, giúp học sinh nông thôn tiếp cận nội dung chất lượng cao. Ngoài ra, Projects tool tạo sách nói giáo dục (e-learning narration) đa ngôn ngữ, hỗ trợ tiếng Việt-Anh cho chương trình quốc tế, giảm thời gian sản xuất từ tuần xuống giờ và tăng engagement 30-40% theo khảo sát Udemy về AI voice trong giáo dục.
6.2 Marketing & Quảng cáo
Thị trường quảng cáo Việt Nam đạt 3 tỷ USD năm 2025, với TikTok và YouTube chiếm 60%, ElevenLabs giúp agency như Golden Communication tạo TVC (quảng cáo truyền hình) nhanh chóng. Sử dụng AI Dubbing, họ dịch và lồng tiếng video sản phẩm từ tiếng Anh sang tiếng Việt, giữ giọng thuyết minh “ấm áp, thuyết phục” để phù hợp văn hóa địa phương. Ví dụ, chiến dịch quảng cáo mỹ phẩm của Shopee Việt Nam dùng voice cloning để nhân bản giọng KOL (Key Opinion Leader) như Chi Pu, tạo nội dung cá nhân hóa cho 10 triệu người dùng miền Nam. Tính năng Voice Changer thêm hiệu ứng vui nhộn cho radio ad, tiết kiệm 80-90% chi phí so với thuê voice talent, đồng thời hỗ trợ A/B testing với đa accent để tối ưu conversion rate.
6.3 Sáng tạo nội dung
Với hơn 20 triệu creator trên TikTok Việt Nam, ElevenLabs là “vũ khí bí mật” cho nội dung ngắn. Creator dùng Voice Lab để clone giọng cá nhân, tạo narration cho video TikTok về du lịch (giọng miền Trung luyến láy) hoặc lồng tiếng nhân vật hoạt hình trên YouTube. Một ví dụ từ Reddit (r/ElevenLabs): Developer Việt xây app dịch voice message, dùng Flash v2.5 để chuyển tiếng Việt sang Anh với emotion giữ nguyên, nhận phản hồi tích cực từ người dùng diaspora. Podcast như “Việt Nam Đêm Nay” sử dụng TTS để tạo episode dài, thêm [whispers] cho phần kể chuyện bí ẩn, tăng lượt nghe 50% nhờ giọng tự nhiên hơn Google TTS. Năm 2025, tích hợp với CapCut giúp creator export audio trực tiếp, thúc đẩy xu hướng “AI-assisted storytelling” trên nền tảng xã hội.
6.4 Chăm sóc khách hàng
Ngành dịch vụ Việt Nam (ngân hàng, e-commerce) đang chuyển sang AI agent, với ElevenLabs’ Conversational AI (ra mắt 2024) xây dựng chatbot thoại 24/7. Ví dụ, Vietcombank tích hợp API để tạo tổng đài tự động với giọng nữ miền Bắc lịch sự, xử lý 70% cuộc gọi (hỏi dư nợ, chuyển khoản) bằng tiếng Việt, giảm chi phí nhân sự 60%. Tính năng real-time (latency 75ms) hỗ trợ multi-speaker dialogue, như “Xin chào, tôi có thể giúp gì?” với emotion [friendly]. Theo báo cáo Salesforce Ventures, các doanh nghiệp Việt như Tiki dùng voice cloning để cá nhân hóa hỗ trợ (giọng giống nhân viên quen thuộc), tăng satisfaction score lên 85%, đặc biệt hữu ích cho khách hàng lớn tuổi quen nghe giọng địa phương.
6.5 Xuất bản
Thị trường audiobook Việt Nam tăng 200% từ 2023-2025 nhờ app như Voiz FM, ElevenLabs hỗ trợ qua Reader app (ra mắt 2025) để tác giả tự publish AI-generated audiobook. Tác giả như Nguyễn Nhật Ánh dùng Projects để chuyển sách “Cho Tôi Xin Một Vé Đi Tuổi Thơ” thành audio với giọng trẻ em miền Nam vui tươi, giữ consistency qua 10 chương. Hỗ trợ multilingual cho sách song ngữ Việt-Anh, giúp xuất khẩu nội dung đến cộng đồng Việt kiều (Mỹ, Úc). Lợi ích: Giảm chi phí sản xuất từ 500 triệu VND xuống dưới 50 triệu, với royalty cao qua ElevenReader, và voice customization để khớp “giọng tác giả” – một case study từ HarperCollins (tương tự Việt) cho thấy tăng doanh số 35%.
6.6 Giải trí
Ngành game và phim Việt Nam (VNG, Garena) dùng ElevenLabs cho dubbing phim Netflix-style. Ví dụ, studio phim Việt như Galaxy dùng AI Dubbing để lồng tiếng “Mai” (phim hoạt hình 2024) sang tiếng Việt từ bản Anh, giữ giọng nhân vật gốc với accent Huế đặc trưng, tiết kiệm 90% thời gian hậu kỳ. Trong game mobile như “Liên Quân Mobile”, tích hợp voice cloning cho nhân vật nói tiếng Việt cảm xúc ( [angry] cho combat), tăng immersion cho 50 triệu người chơi. Một bài đăng trên X từ @cangg_l (Oct 2025) đề cập tích hợp ElevenLabs vào Kindred AI cho game dev Việt, kết hợp NVIDIA để tạo voice agent scale. Điều này hỗ trợ nội dung giải trí địa phương, như podcast hài kịch với voice changer cho hiệu ứng vui nhộn.
6.7 Phát triển phần mềm
Với hơn 100.000 developer Việt trên GitHub, ElevenLabs API dễ tích hợp vào app như chatbot Zalo OA hoặc website e-learning. Ví dụ, startup Việt Sparkout Tech dùng SDK để xây e-learning app với real-time voice feedback, hỗ trợ tiếng Việt đa accent cho học viên miền núi. REST API cho phép thêm features như voice isolator (loại nhiễu) vào app ghi âm, phù hợp phát triển mobile (React Native). Theo Contrary Research, 41% Fortune 500 dùng ElevenLabs cho enterprise comms, và tại Việt Nam, các công ty như FPT Software tích hợp vào VR training, giảm chi phí 70% so với voice actor. Năm 2025, hỗ trợ 70+ ngôn ngữ giúp dev Việt export app toàn cầu, với ethical guidelines để tránh misuse.



